206-886-0416
206-886-0416

This is written with the intent to help my fellow readers get their foot in the door in software development. The question is, how can I work towards making a decent living in the world of software development? Obviously, the most important thing in any career is a good work ethic. Hard work and hours and hours spent studying will definitely increase anyone's chances of being successful in their area of expertise. Of course, there are absoultely no guarantees in life and all that time could have been spent studying and working with five million job applications sent with not one decent job offer.
Of course, we want to decrease the chances of this from happening as much as possible. That's where hard work comes in. Of course, luck will also play a factor but we can't control that, so let's talk about what we *can* control. Even viewing this from a mathematical or probabilistic lens, if 30% of success comes down to chance and 70% of it comes down to the person (i.e., the resume, the work ethic, the past works, the reputation of the school that the person (hopefully) attended, the grades achieved in school, the awards, the scholarships, etc.), since we can't change the 30% that stays constant, then we can maximize the remaining portion of the probabilistic pie to increase our chances of success. And, we know that we have fully-employed software developers and engineers in the world that are employed in real, big, and successful centibillion or trillion-dollar market capitalization corporations (e.g., FAANG—Facebook (now Meta), Amazon, Apple, Netflix, and Google (now Alphabet)), so we know that we are not being asked to build another planet here.
The world after postsecondary school may be intimidating for students that did relatively well in postsecondary school with few barriers to success (aside from hardcore studying). I want to best assist my readers in breaking down a long and arduous journey towards a success that is not guaranteed to be there into manageable sections:
1) The different kinds of software development.
2) The most sought-after tech skills in each type of software development.
3) How to best acquire the vast amounts of knowledge required in the highly sought-after skills in a condensed time frame (six months).
4) How to create an eye-catching portfolio of past works to present to your future employers.
5) How to gain experience by freelancing.
6) Job boards that I recommend.
7) Examples of real work that you would be doing at a business or company.
1) The Different Kinds of Software Development
I want to first explain the different kinds of software development that exist. I would say that almost all software development can be neatly categorized into three different kinds of development: mobile app development (iOS/Android), web development, and desktop software development. With that in mind, I recommend searching job boards and freelancing platforms for current job openings to see which kind of software development is most in-demand and choose one that you want to become an expert in.
2) The Most Sought-After Tech Skills in Each Type of Software Development
We can now discuss the tech skills that are most in-demand in each kind of software development. Firstly, in mobile app development, which can be further divided into iOS app development and Android app development, I would say that to code iOS apps well, you would have to be good with swift. For Android apps, you would have to be good with Java. For web development, you would have to be good with both front-end web development and back-end web development which mainly consists of HTML5, CSS3, JavaScript, jQuery, AngularJS 8, Bootstrap 5, and AJAX (for front-end) and PHP 8, JSON, SQL, MariaDB, MySQL, Python 3.10.5, Selenium, and Heroku (remote app deployment) (for back-end). For desktop software development, you would have to be skilled with C/C++, Java, Python, Ruby on Rails, PHP, Perl, and more.
3) How to Best Acquire the Vast Amounts of Knowledge Required in the Highly Sought-After Skills in a Condensed Time Frame (Six Months)
I would now start with acquiring the knowledge necessary to perform work in this field at an all-star level. This means exhausting all resources that you have available to you. This includes YouTube (tutorials), search engine (e.g., Google) searches, Stack Overflow questions and answers, W3Schools.com modules, and textbooks. For textbooks, I personally used and recommend the Sams Teach Yourself series. After becoming proficient in the tech stacks that are highly sought after in today's job market (e.g., PHP 8, JSON, SQL, MariaDB, MySQL, Python 3.10.5, Selenium, and Heroku (remote app deployment) (for back-end) and HTML5, CSS3, JavaScript, jQuery, AngularJS 8, Bootstrap 5, and AJAX (for front-end)), I would start producing a portfolio of past works to present on freelancing platforms.
4) How to Create an Eye-Catching Portfolio of Past Works to Present to Your Future Employers
Here are the following works that you can complete for your portfolio:
> Use python and selenium to scrape eBay for all models of the vehicle make Audi produced in any year that sold in any year. Then, output the average price of the Audi (all models and production years and sold in any year).
Prerequisites:
- Basic understanding of the latest version of python
- Knowledge of dynamic website scraping using a python module called Selenium
> Producing a login and registration page with a fully-functional back-end database information storage and retrieval system
Prerequisites:
- HTML5, CSS3, JS, and Bootstrap 5 to build the front-end
- MySQL, SQL, and PHP 8 (to execute SQL statements on the back-end)
Additional Information:
The MySQL database would include a column for the username and another column for the password (just two columns for this beginner work purpose). The password will be hashed. I recommend following an online guide like https://speedysense.com/create-registration-login-system-php-mysql/. The process would basically involve making the database, a table in the database with two columns, then inserting data into the database. To be more specific, it would involve producing an HTML5 form which upon submission will direct to a PHP 8 page that will use the data from the user-submitted HTML5 form to produce SQL statements that use that data which will be inserted into the database that we have created. The exact details on this process are highly technical and so I recommend the link that I mentioned previously and also referring to YouTube tutorials and the Sams Teach Yourself textbook for any questions.
5) How to Gain Experience by Freelancing
To gain experience by freelancing, I would start by searching for freelancing platforms that require software developers or software engineers on search engines like Google. I personally use and recommend freelancer.com, guru.com, upwork.com, and fiverr.com. Setting up a profile on these freelancing platforms to get experience for your full-time permanent job at a bigger company should be a doable task if you completed the previous steps. I would start by presenting your portfolio of past works that you think future employers would like and then filling in your education credentials. I would also include any previous related work experience (if any). The average employer must notice that you are capable of producing good work before hiring you.
6) Job Boards That I Recommend
My personal recommendations are monster.ca, indeed.ca, angel.co, linkedin.com, and ziprecruiter.com.
7) Examples of Real Work That You Would Be Doing at a Business or Company
In the real world, you would most likely be asked to work in an environment in which businesses or companies are selling products or services. An example business/company we will study is Beauty Collection Inc. It's a store located in Toronto, ON. In this case, a worker might be asked to use a front-end web development tech stack and a back-end web development tech stack to work on their existing sales platform.
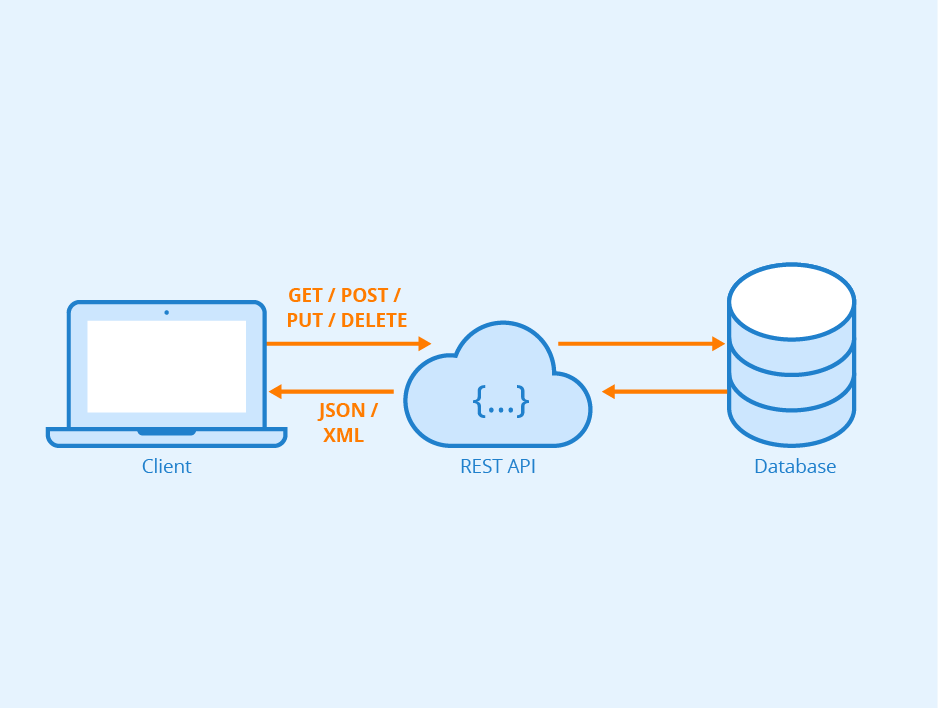
You would work on either the front-end, the back-end, or both (full-stack). Front-end is basically what you see on the front (the side facing the client) and back-end is what you don't see (e.g., the data stored on the back-end). In the case of Beauty Collection Inc., this would involve data of the products (e.g., hair products) being stored in a database (e.g., MySQL). This would then later need to be retrieved using something like SQL statements, transferred to the client side, and then finally displayed on the client side/front-end.
Hopefully I have helped my readers break down their journey into success in the world of software development into manageable sections. I encourage my readers to think of their journey as long-term and not expect immediate results :).